
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 크롤링
- cmd
- web
- Jango
- DBFIDDLE
- 멋쟁이사자처럼
- 서류합격
- likelion
- 장고
- 아기사자
- 해커톤
- Crawling
- 멋사
- 파이썬
- 동아리
- 코딩
- copy selector
- 지원서
- HTML
- 코딩연합동아리
- Django
- scraping
- 웹
- Python
- html.parser
- 이두희
- 백엔드
- 9기
- 대외활동
- 10기
- Today
- Total
olbiizl_.tistory.com
프로젝트(3)_파이썬 웹 크롤링(Session,select,text) 본문
진짜 본격적으로 크롤링을 시작하도록 하겠습니다 !
일단 앞에서 배운 내용을 바탕으로
크롤링을 위한 모듈을 import한 후 코드를 작성해주면 됩니다.
잊지 않으셨겠죠 ??
Python에서 HTTP 요청을 보내는 모듈인 requests 모듈과
파이썬으로 웹을 크롤링해서 파싱할 수 있게 만들어주는 오픈소스 라이브러리인
beautifulsoup 라이브러리를 사용하기 위해
코드의 맨 첫 줄에 import문을 작성합니다.
import requests from bs4 import BeautifulSoup as bs
이 때 as bs 는 앞으로 BeautifulSoup를 사용할 때에
편의성을 위해 bs 를 사용하겠다는 뜻입니다.
저희가 크롤링할 페이지는
로그인이 꼭 필요한 페이지입니다.
따라서 로그인을 한 후에 나오는 페이지를
크롤링하기 위해서는 로그인할 정보를 url에 데이터로 넘겨주어야 합니다.
넘길 데이터를 dictionary 형태로 넣어줄건데요
user_info = { 'username' = '2020XXXXX' 'password' = '*********' }
user_info 딕셔너리 안에
username 변수에는 아이디를,
password 변수에는 비밀번호를 적어
딕셔너리 형태의 user_info를 만들어줍니다.
이 때 변수의 이름은 맘대로 설정하는 것이 아니라는 점을 주의해줘야 합니다 !

로그인을 위한 텍스트 박스 안의 html을 살펴보면
아이디를 입력하는 칸과 비밀번호를 입력하는 칸 각각에
주어진 name(id)가 존재합니다.
콘솔창을 띄운 뒤 사진 속 아이디 입력 칸의 html 파일을 살펴보면
name="username" 인 것을 볼 수 있죠 ?
그렇기 때문에 위의 user_info 딕셔너리에서 변수 이름을 username으로 설정해준 것입니다.
다음으로 우리는 앞에서 선언한 requests 모듈에 있는 Session이라는 도구를 활용할거예요!
사용자가 로그인을 하면 로그인한 사용자에 대해 세션을 생성하게 됩니다.
세션 아이디는 웹 브라우저 당 한 개씩 생성되고,
이 세션 아이디는 웹 컨테이너에 저장됩니다.
Session은 사용자 또는 다른 사용자들에게 노출되지 않아야 하는 정보들을
서비스 제공자가 직접적으로 관리할 수 있는 장점이 있답니다 !
이러한 세션을 사용하기 위해
requests.Session()을 사용해줄 것이고,
이 세션을 크롤링 하는 동안 유지시켜주기 위해 with문과 함께 사용합니다.
//requests.Session()을 편리를 위해 s로 사용하겠다는 뜻 with requests.Session() as s:
아이디와 비번이 담긴 딕셔너리 변수도 만들었고, 세션도 만들었으니
크롤링할 url에 user_info를 전달하고 파싱작업을 위해 beautifulsoup 작업까지 해줄겁니다.
with 구문 안에서 작업이 이루어져야 하니 위의 코드와 합쳐주면
with requests.Session() as s: request = s.post('http://ecampus.smu.ac.kr/login/index.php', data=user_info) source = request.text soup = bs(source, 'html.parser')
이와 같은 코드가 완성됩니다.
(LINE 2)
data에 앞에서 선언한 user_info를 넣어준 후
data값을 로그인할 페이지의 url에 post 형태로 전달하고
HTML 내용을 응답받습니다.
(LINE 3)
응답받은 HTML 내용을 Unicode 형태로 변환하기 위해
request.text 를 사용해준 후 source 변수에 넣어줍니다.
(LINE 4)
beautifulsoup 객체를 통해 source html를 파싱하기 위해
bs 작업을 해줍니다.
이제 파싱 작업까지 마무리를 해주었다면
원하는 곳의 html만을 파싱하기 위해 select 작업을 해줍니다.
저희는 로그인한 후의 페이지에서
강의의 목록만을 출력해볼거에요.

저희는 h3 태그에 해당되는 강의 제목만을 출력할 것이기 때문에
해당 태그의 경로를 알아야합니다.

해당 html 태그에서 우클릭을 한 후에
copy selector을 클릭하면
#region-main > div > div.progress_courses > div.course_lists > ul > li:nth-child(1) > div > a > div.course-name > div.course-title > h3
위와 같이 태그의 경로가 복사되게 됩니다.
위에서 li:nth-child(1)을 그대로 넣게 되면
첫 번째 h3 태그의 내용만 출력됩니다.
우린 저 페이지에 있는 강의 목록을 모두 출력해야 하기 때문에
(1)을 없앤 후에 select 작업을 진행해주면 됩니다.
top_list = soup.select("#region-main > div > div.progress_courses > div.course_lists > ul > li > div > a > div.course-name > div.course-title > h3")
위와 같이 해당 태그를 select 한 내용을 top_list 변수에 넣어주고
top_list를 출력하면

해당 h3 태그에서 태그의 이름까지 모두 출력이 됩니다.
top_list에서 태그를 제외한 내용만 출력하기 위해
for top in top_list: print(top.text)
반복문을 통해 text 작업을 거쳐주면
강의 목록만 깔끔하게 출력하게 됩니다.
import requests from bs4 import BeautifulSoup as bs #beautifulsoup대신 bs 사용하겠다는 뜻 user_info = { 'username' : '2020XXXX', 'password' : '********' } with requests.Session() as s: request = s.post('https://ecampus.smu.ac.kr/login/index.php', data=user_info) source = request.text soup = bs(source,'html.parser') top_list = soup.select("#region-main > div > div.progress_courses > div.course_lists > ul > li > div > a > div.course-name > div.course-title > h3") print("❤당신이 듣고 있는 강의들입니다❤\n") for top in top_list: print(top.text)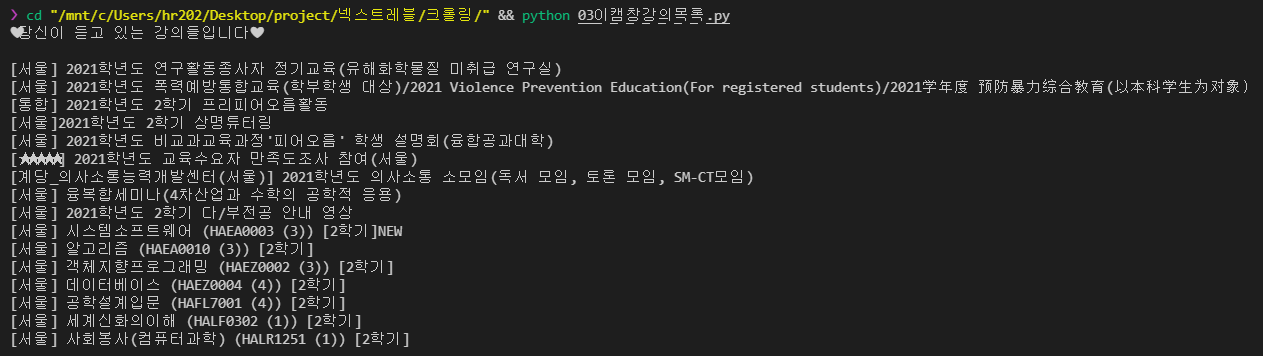
앞으로 다른 페이지를 크롤링할 때에도
같은 방법으로 진행되기 때문에 첫 단추만 잘 끼운다면
다른 페이지의 다른 html을 파싱하는 작업을 하더라도
수월하게 진행할 수 있을거라고 생각합니다 !
하다보면 정말 뿌듯하고 재미있는 크롤링이기 때문에
차근차근 다른 페이지에서 적용하면서 따라해보시고
출력도 한 번 꼭 해보세요 !!
오류가 생긴다면 중간중간 변수를 print 하면
어디에서 문제가 발생하는지 알 수 있기 때문에
하나씩 천천히 진행해보시길 바랍니다.
여러분의 첫 크롤링이 성공적이었길 바라며
다른 페이지의 다른 태그들을 파싱하는 내용으로
다시 한 번 찾아오겠습니다.
오늘도 화이팅 :)

'CRAWLING + DISCORD BOT' 카테고리의 다른 글
| 프로젝트(2)_파이썬 웹 크롤링_개발환경설치 (0) | 2021.09.30 |
|---|---|
| 프로젝트(1)_NEXT LEVEL 소개글 (0) | 2021.09.30 |

